This is a complete summary of an excellent talk by Rob Pike “Concurrency is Not Parallelism”. Illustrations and diagrams are recreated; source code taken verbatim from the slides, except for comments, which were extended in some places.
(You can get a set of PDF (preview)/HTML/epub/Kindle versions below. Name your price, starting from $1.)
Intro
The world is parallel: starting from the computing fundamentals, such as multi-core CPUs, and all the way to real life objects, people, planets and the Universe as a whole — everything is happening simultaneously. Yet, the computing tools that we have aren’t good at expressing this world view. We can rectify this by exploring concurrency.
Go is a concurrent language. It makes it easy to design concurrent systems by providing the ability to:
- execute things concurrently
- communicate between concurrently running processes
There’s a misconception about Go and concurrency: many programmers believe concurrency and parallelism are the same thing. They are not, and this talk will try to answer why.
Concurrency vs parallelism
Here’s the core of the distinction:
Concurrency is composition of independently executing things (typically, functions). We often use the word ‘process’ to refer to such running thing, and we don’t mean ‘unix process’, but rather a process in the abstract, general sense.
Parallelism is simultaneous execution of multiple things. Those things might or might not be related to each other.
Concurrency is about dealing with a lot of things at once. Parallelism is about doing a lot of things at once. The ideas are, obviously, related, but one is inherently associated with structure, the other is associated with execution. Concurrency is structuring things in a way that might allow parallelism to actually execute them simultaneously. But parallelism is not the goal of concurrency. The goal of concurrency is good structure.
Analogy
The operating system manages multiple devices at the same time (disk, screen, keyboard, etc). They are somewhat independent and completely concurrent concerns. However, they aren’t necessarily parallel: if the computer has only one core, several things can’t possibly run simultaneously. The model here is concurrent, it is structured as a system of concurrent processes. Its reality could be parallel, depending on circumstances.
Compare this to performing matrix multiplication on a powerful GPU which contains hundreds or thousands of cores. Both the underlying idea and the reality are parallel, it’s all about running operations at the same physical time.
Concurrency allows to structure the system in such a way that enables possible parallelism, but requires communication. Tony Hoare has written “Communicating sequential processes” (https://www.cs.cmu.edu/~crary/819-f09/Hoare78.pdf) in 1978, where he describes problems and techniques of dealing with these issues. It is the greatest paper in computer science and we highly recommend every programmer to read it. Programming languages like Erlang and Go are largely based on ideas described in it.
Concurrent composition
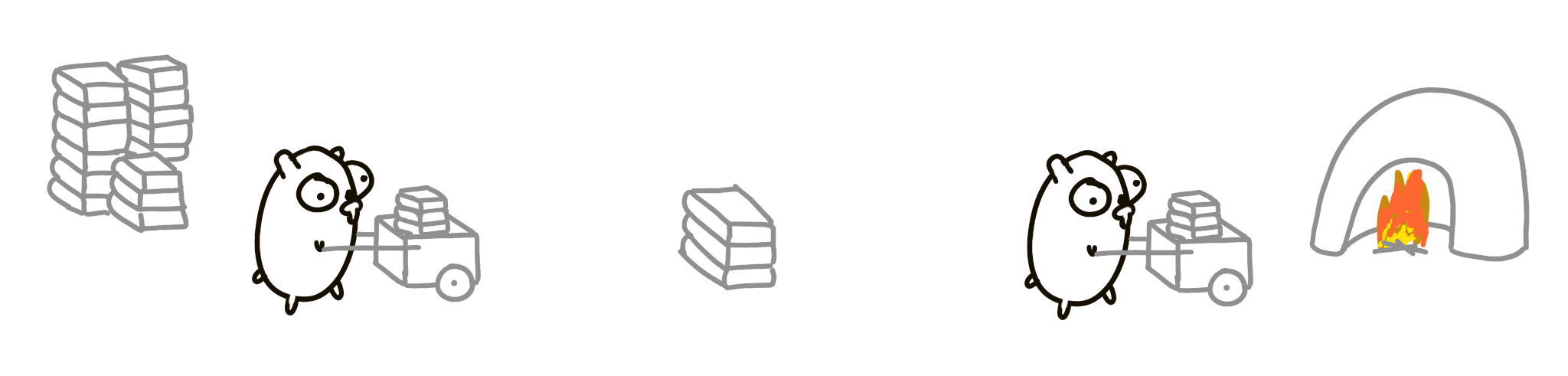
There’s a pile of books we need to burn. We have a gopher whose job is to move books from the pile to the incinerator.

One gopher is slow, so let’s add another gopher. But now we need to synchronize them, since they might bump into each other, or get stuck at either side. One way to solve this is to make them communicate with each other by sending messages (like, “I’m at the pile now” or “I’m on my way to the incinerator”).
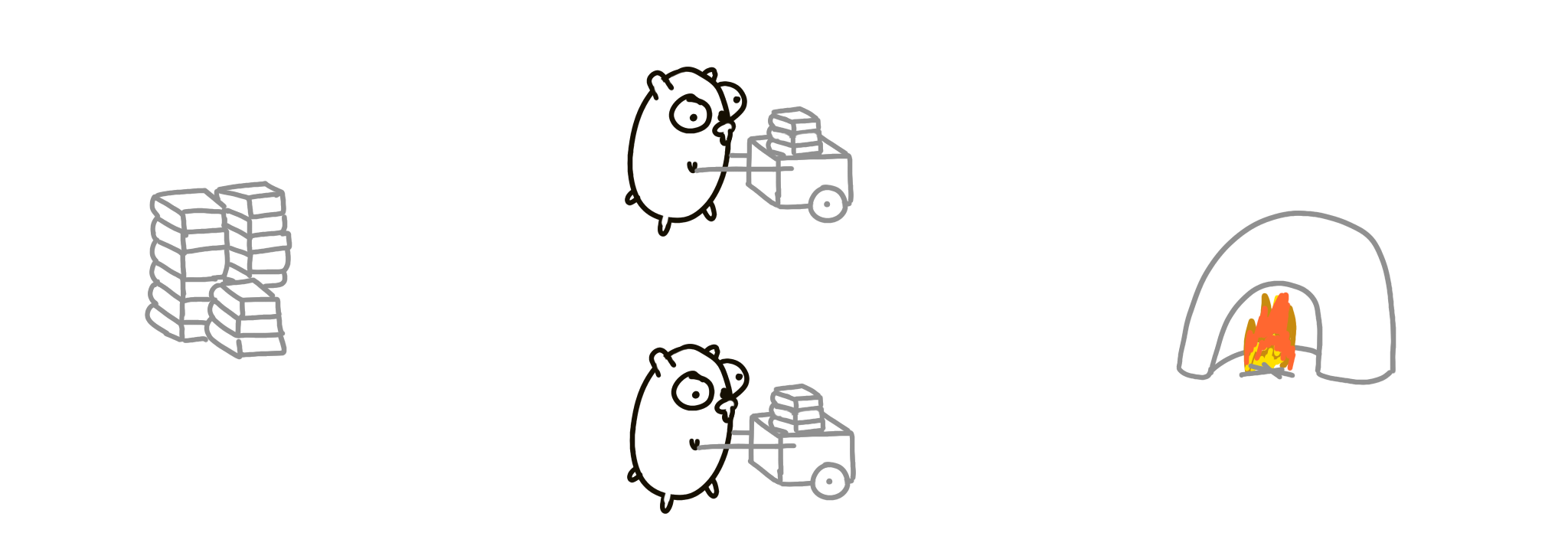
How can we go faster? Double everything! Two piles of books, two incinerators! Consumption and burning can be twice as fast now. That’s parallel.

But try to think about it as the composition of two gopher processes. We start with a single process, and then just introduce another instance of the same process. This is called concurrent composition.
While not immediately obvious, concurrent composition is not automatically parallel! It’s possible that only one gopher moves at a time. The design is still concurrent, but not parallel. This is similar to the OS example on a single core processor, where two concurrent things might not run in parallel due to technical limitations.
However, concurrent composition is automatically parallelizable.
Different design
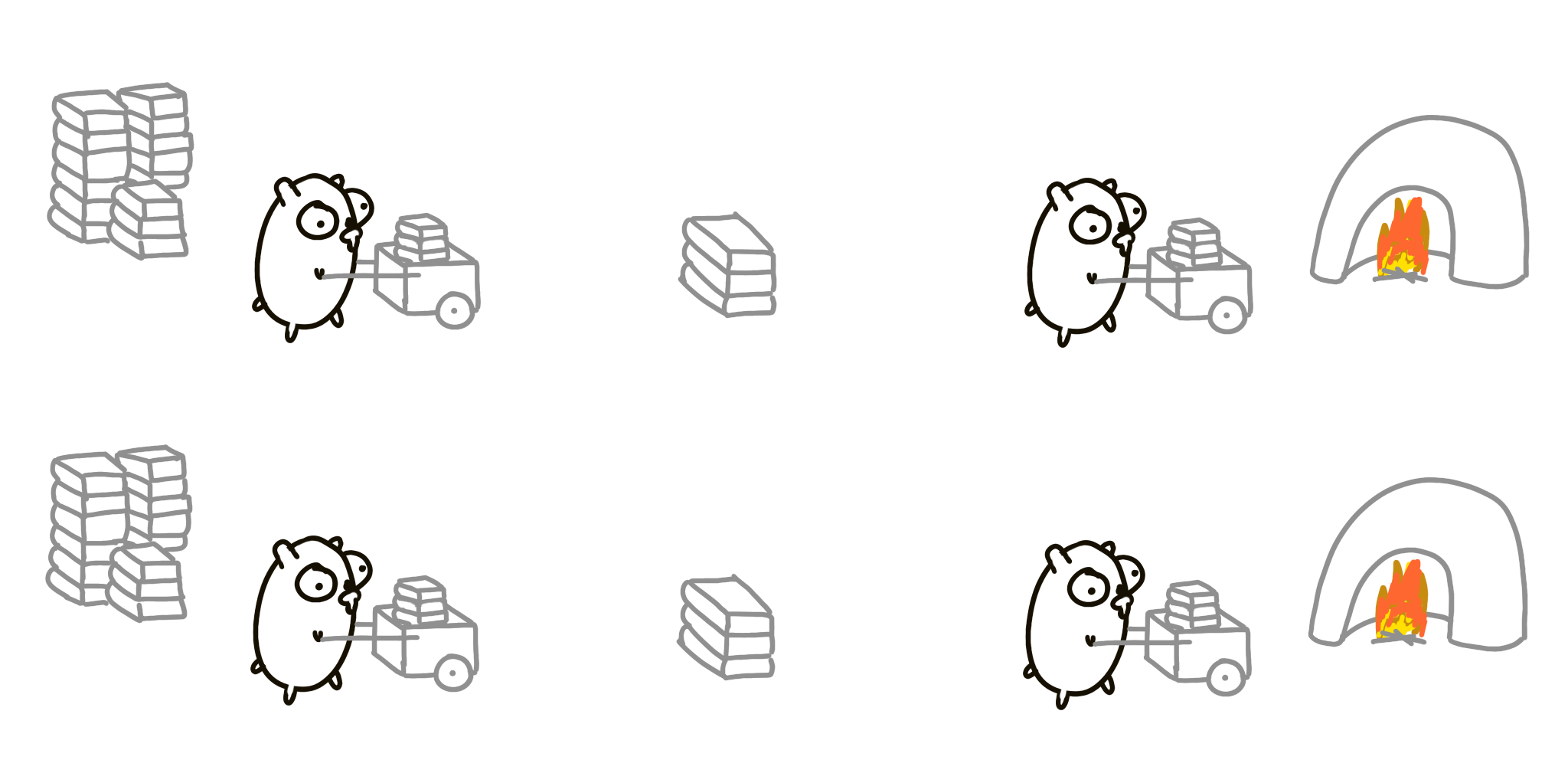
Let’s try another approach. There will be three gophers in total:
- One only loads the cart.
- Another runs the cart to and from the incinerator.
- The third unloads the cart.
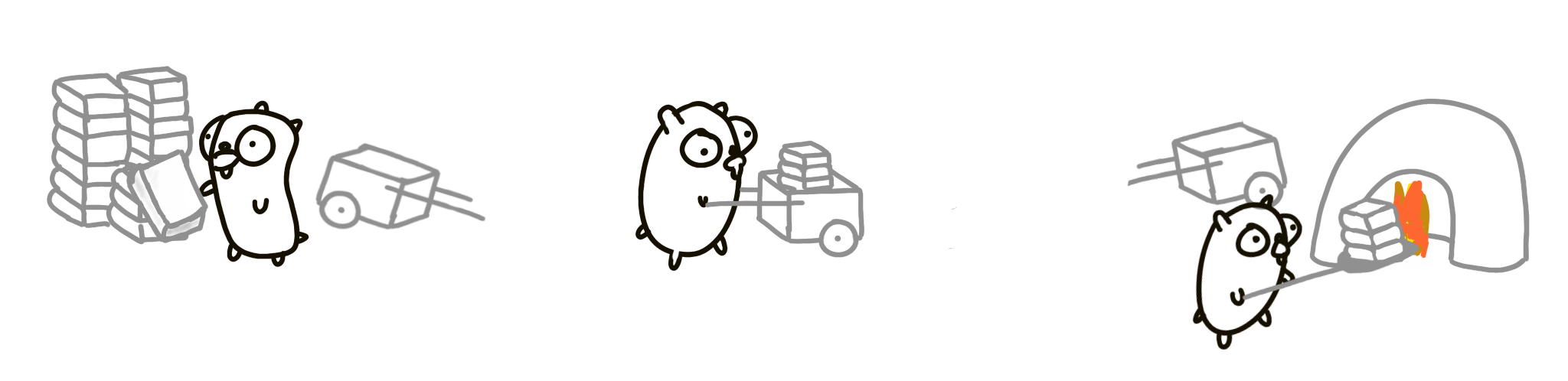
Each gopher is an independently executing procedure.
This approach is probably faster, although, not by much. There’ll definitely be problems like blocking, unnecessary waiting when the books are being loaded and unloaded, the time when the 2nd gopher runs back and nothing useful is happening, etc. Let’s add another gopher!
Finer-grained concurrency
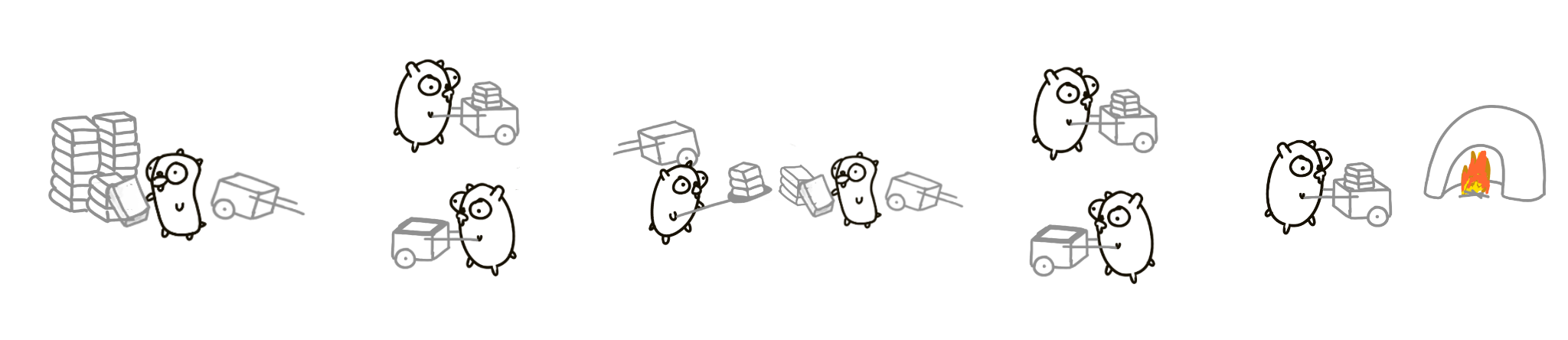
Now there’s a 4th gopher who returns the empty cart
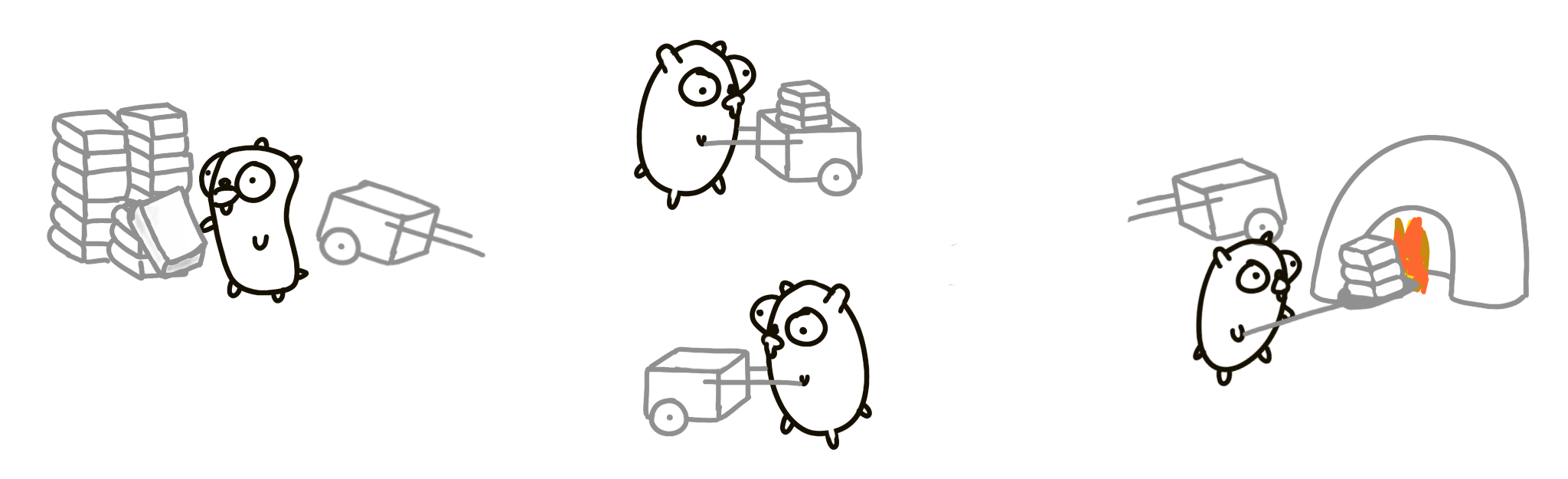
This version of the problem will work better than the previous version, even though we’re doing more work. Concurrent composition of better managed pieces can run faster. In the perfect situation, with all settings optimal (number of books, timing, distance), this approach can be 4 times faster than the original version.
This is important! We improved the performance of this program by adding a concurrent procedure to existing design. We added more things and it got faster! The reason it can run faster is that it can be parallel, and the reason it can be parallel is better concurrent design.
So, we have four distinct gopher procedures:
- Load books onto cart.
- Move cart to incinerator.
- Unload cart into incinerator.
- Return empty cart.
Think of them as of independent procedures, running on their own, and we compose them in parallel to construct the solution. We can make it more parallel by, well, parallellizing the whole thing:
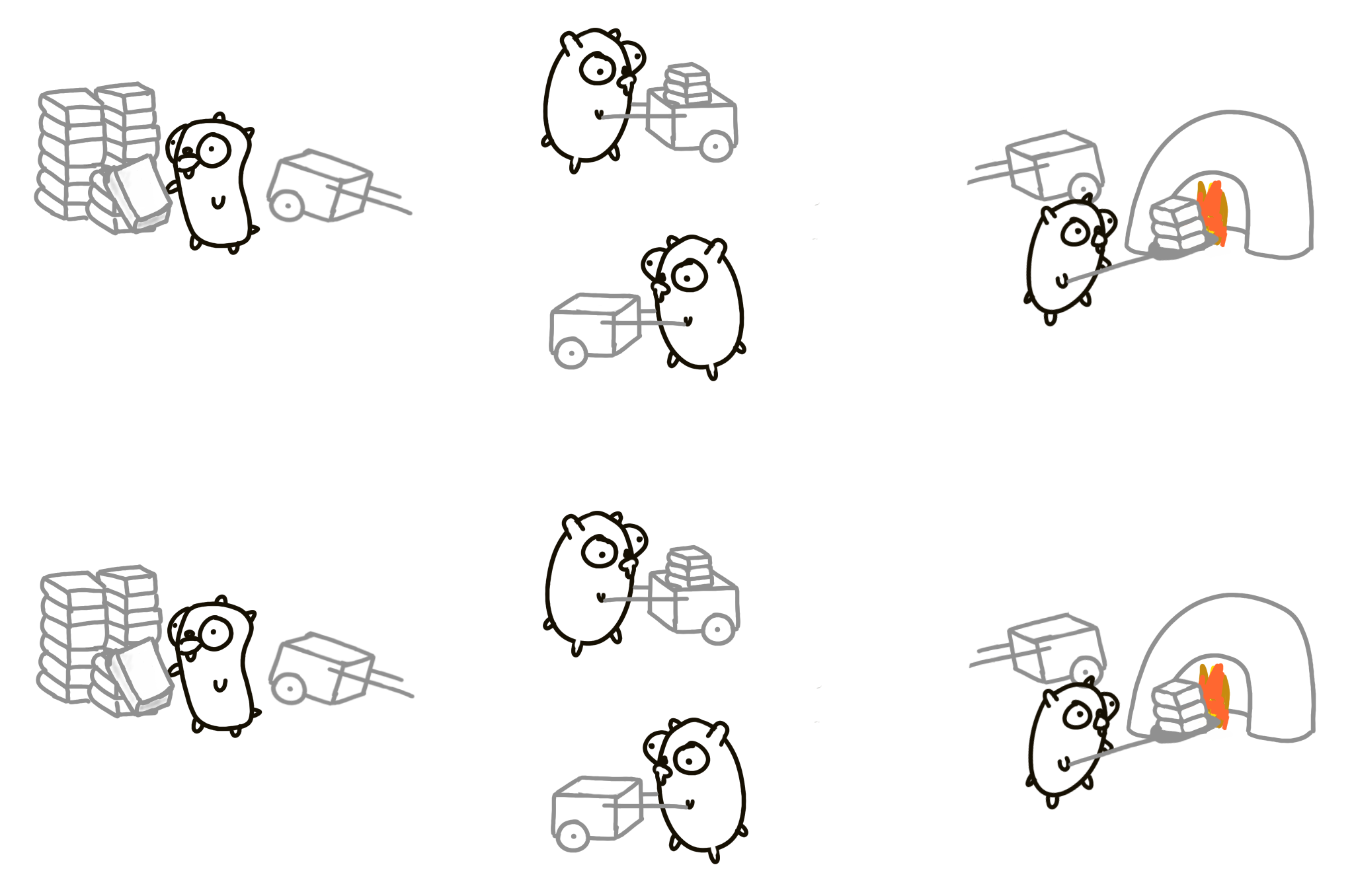
Note what we’re doing here: we have a well composed system which we then parallelize on a different axis to, hopefully, achieve better throughput. We understand the composition and have control over the pieces.
And what if gophers can’t run simultaneously (back into the single core world)? No problem, really. Only one gopher runs at a time, and 7 others are idle. The system runs as fast as a single gopher and the overall speed is the same as the first solution. But the design is concurrent, and it is correct. This means we don’t have to worry about parallelism if we do concurrency right. Parallelism is optional.
Yet another design
Two gophers with a staging dump in the middle.
Two similar gopher procedures running concurrently. In theory, this could be twice as fast. As before, we can parallelize it and have two piles with two staging dumps.
Or try a different design still: 4 gopher approach with a single staging dump in the middle.
And then double that! 16 gophers, very high throughput.
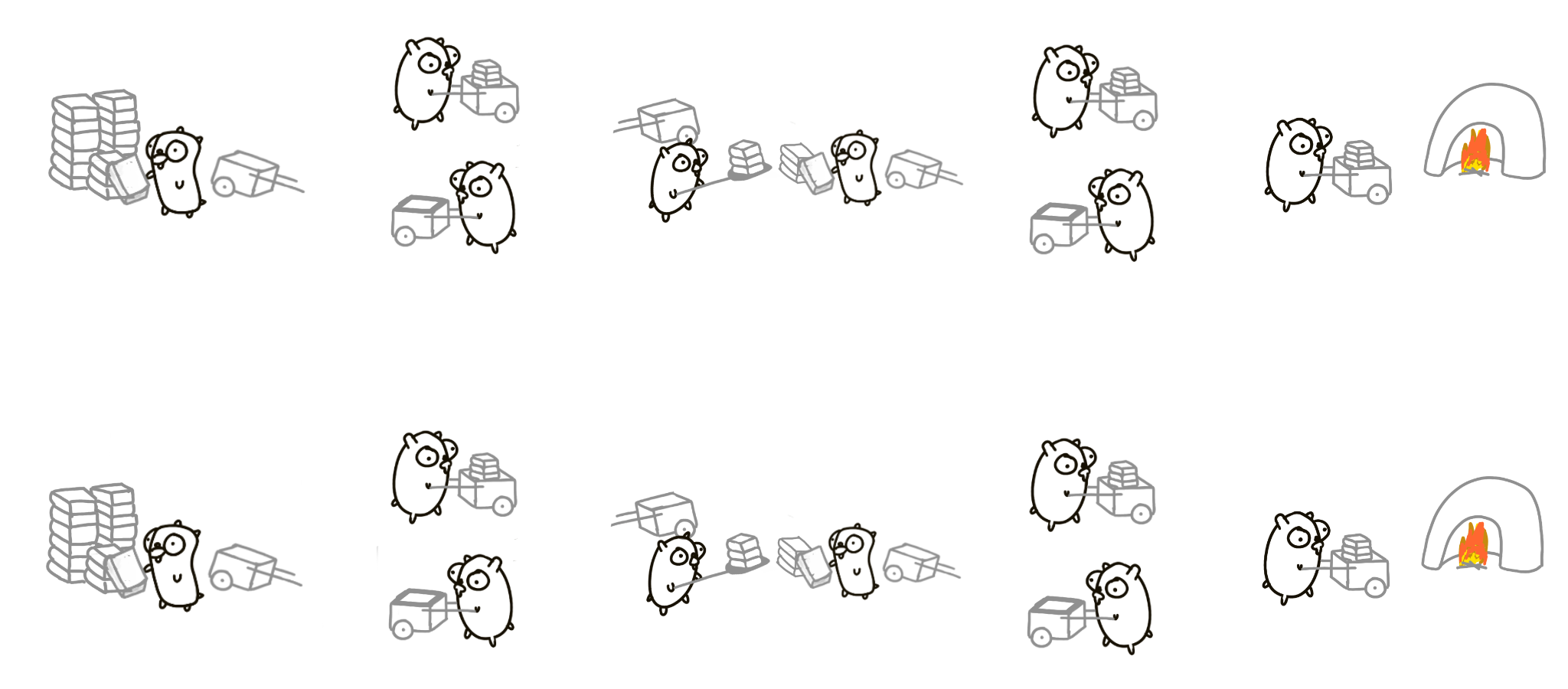
Obviously, this is very simplistic and silly. But conceptually this is how you think about problems: don’t think about parallel execution, think about breaking down the problem into independent components, and then compose in a concurrent manner.
Summary
There are many ways to break the process down. You can easily come up with a dozen more structures. That is concurrent design. Once we have the breakdown, parallelization can fall out and correctness is easy to achieve. The design is intrinsically safe.
Real world example
This gophers example might look silly, but change books to web content, gophers to CPUs, carts to networking and incinerators to a web browser, and you have a web service architecture.
Let’s learn a little bit of Go.
Goroutines
If we run a regular function, we must wait until it ends executing. But if you put a keyword go in front of the call, the function starts running independently and you can do other things right away, at least conceptually. Not necessarily, remember: concurrent is not the same as parallel.
f("Hello") // f runs, we wait
go f("Hello") // f starts running
g() // we don't wait for f to return
(This is similar to running a background shell process with &).
It is common to create thousands of goroutines in one Go program. There could be millions! Goroutines aren’t free, but they’re very cheap.
Channels
Under the hood, goroutines are like threads, but they aren’t OS threads. They are much cheaper, so feel free to create them as you need. They are multiplexed onto OS threads dynamically, and if one goroutine does stop and wait (for example, for input/output operation), no other goroutines are blocked because of that.
To communicate between goroutines we use channels. They allow goroutines exchange information and sync.
Here’s an example. We create a timerChan channel of time.Time values (channels are typed). Then we define and run a function func which sleeps for some time deltaT and sends current time to the channel. Then, some time later, we receive a value from the channel. This receiving is blocked until there’s a value. In the end, completedAt will store the time when func finished.
timerChan := make(chan time.Time)
go func() {
time.Sleep(deltaT)
timerChan <- time.Now() // send time on timerChan
}()
// Do something else; when ready, receive.
// Receive will block until timerChan delivers.
// Value sent is other goroutine's completion time.
completedAt := <-timerChan
Select
Goroutines and channels are the fundamental building blocks of concurrent design in Go. The last piece is the select statement. It is similar to a simple switch, but the decision is based on ability to communicate instead of equality.
The following example produces one of three outputs:
- If channel
ch1is ready (has a value), first case executes. - If channel
ch2is ready (has a value), second case executes. - If neither is ready, the default case executes.
select {
case v := <-ch1:
fmt.Println("channel 1 sends", v)
case v := <-ch2:
fmt.Println("channel 2 sends", v)
default: // optional
fmt.Println("neither channel was ready")
}
If the default clause is not specified in the select, then the program waits for a channel to be ready. If both ready at the same time, the system picks one randomly.
Closures
Go supports closures, which makes some concurrent calculations easier to express. Closures work as you’d expect. Here’s a non-concurrent example:
func Compose(f, g func(x float) float)
func(x float) float {
return func(x float) float {
return f(g(x))
}
}
print(Compose(sin, cos)(0.5))
Examples
Launching daemons
Here we use a closure to wrap a background operation without waiting for it. The task is to deliver input to output without waiting. The following code copies items from the input channel to the output channel.
go func() { // copy input to output
for val := range input {
output <- val
}
}()
The for range runs until the channel is drained (i.e. until there are no more values in it).
Simple load balancer
You have some jobs. Let’s abstract them away with a notion of a unit of work:
type Work struct {
x, y, z int
}
A worker task has to compute something based on one unit of work. It accepts two arguments: a channel to get work from and a channel to output results to. It then loops over all values of the in channel, does some calculations, sleeps for some time and delivers the result to the out channel.
func worker(in <-chan *Work, out chan<- *Work) {
for w := range in {
w.z = w.x * w.y
Sleep(w.z)
out <- w
}
}
Because of arbitrary sleeping time and blocking, a solution might feel daunting, but it is rather simple in Go. All we need to do is to create two channels (in, out) of jobs, call however many worker goroutines we need, then run another goroutine (sendLotsOfWork) which generates jobs and, finally run a regular function which receives the results in the order they arrive.
func Run() {
in, out := make(chan *Work), make(chan *Work)
for i := 0; i < NumWorkers; i++ {
go worker(in, out)
}
go sendLotsOfWork(in)
receiveLotsOfResults(out)
}
This solutions works correctly whether there is parallization or not. It is implicitly parallel and scalable. The tools of concurrency make it almost trivial to build a safe, working, scalable, parallel design. There are no locks, mutexes, semaphores or other “classical” tools of concurrency. No explicit synchronization!
Another load balancer
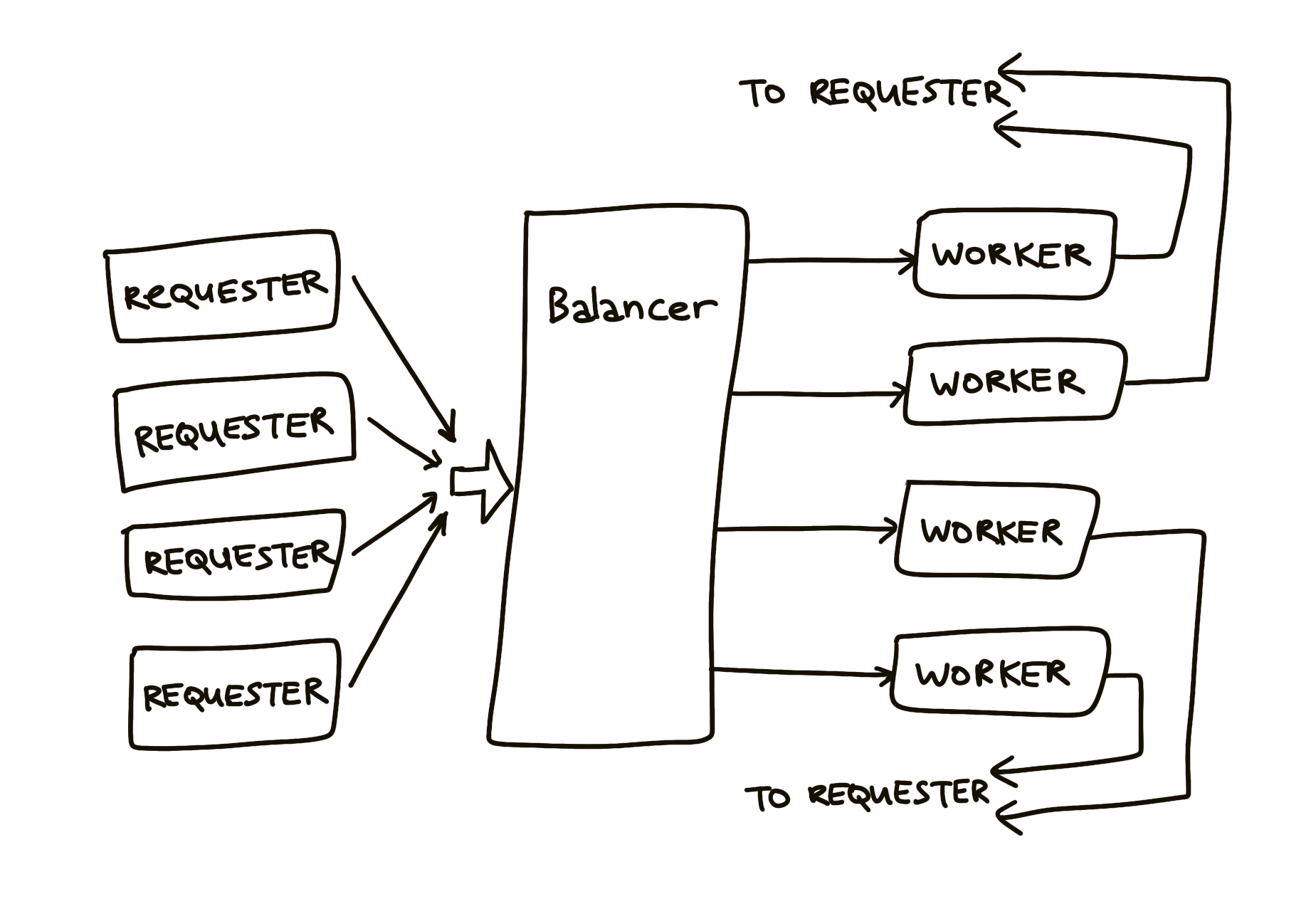
The load balancer needs to distribute incoming work between workers in an efficient way. The requester sends Requests to the balancer:
type Request struct {
fn func() int // The operation to perform.
c chan int // The channel to return the result.
}
Note that the request contains a channel. Since channels are first-class values in Go, they can be passed around, so each request provides its own channel into which the result should be returned.
Now the requester function. It accepts a work channel of Requests. It generates a channel c which is going to get inside the request. It sleeps for some time. Then it sends on the work channel a request object with some function and channel c. It then waits for the answer, which should appear in channel c, and does some further work.
func requester(work chan<- Request) {
c := make(chan int)
for {
// Kill some time (fake load).
Sleep(rand.Int63n(nWorker * 2 * Second))
work <- Request{workFn, c} // send request
result := <-c // wait for answer
furtherProcess(result)
}
}
Now, the worker which accepts Requests is defined by three things:
- The channel of Requests. This is a per-worker queue of work to do.
- Number of pending tasks (the load).
- An index.
type Worker struct {
requests chan Request // work to do (buffered channel)
pending int // count of pending tasks
index int // index in the heap
}
This is what the worker does:
func (w *Worker) work(done chan *Worker) {
for {
req := <-w.requests // get Request from balancer
req.c <- req.fn() // call fn and send result
done <- w // we've finished this request
}
}
Balancer sends requests to most lightly loaded worker. The channel of requests (w.requests) delivers requests to each worker. The balancer tracks the number of pending requests. Each response goes directly to its requester. Once that is done, the balancer is out of the picture, because each worker communicates with its request via a unique channel.
Balancer is defined by a pool of workers and a single done channel through which the workers are going to tell the balancer about each completed request.
type Pool []*Worker
type Balancer struct {
pool Pool
done chan *Worker
}
This is what the balancer does:
func (b *Balancer) balance(work chan Request) {
for {
select {
case req := <-work: // received a Request...
b.dispatch(req) // ...so send it to a Worker
case w := <-b.done: // a worker has finished ...
b.completed(w) // ...so update its info
}
}
}
It runs an infinite loop, forever checking whether there’s more work to do (i.e. there’s an item on the work channel), or there’s a finished task (i.e. there’s an item on the done channel). If there’s work, dispatch it to a worker. If a job is done, update its info.
To allow the balancer to find the lightest loaded worker, we construct a heap of channels and providing methods such as:
func (p Pool) Less(i, j int) bool {
return p[i].pending < p[j].pending
}
We’re ready to implement the dispatcher:
// Send Request to worker
func (b *Balancer) dispatch(req Request) {
// Grab the least loaded worker...
w := heap.Pop(&b.pool).(*Worker)
// ...send it the task.
w.requests <- req
// One more in its work queue.
w.pending++
// Put it into its place on the heap.
heap.Push(&b.pool, w)
}
All it needs to do is:
- Grab the least loaded worker off the heap.
- Send it the task by writing into its
requestschannel. - Increment its load counter.
- Push it back into the heap.
That’s it!
The final piece is the completed function which is called every time a worker finishes processing a request. It’s essentially the inverse of dispatch:
// Job is complete; update heap
func (b *Balancer) completed(w *Worker) {
// One fewer in the queue.
w.pending--
// Remove it from heap.
heap.Remove(&b.pool, w.index)
// Put it into its place on the heap.
heap.Push(&b.pool, w)
}
Lessons
- A complex problem can be broken down into easy-to-understand components.
- The pieces can be composed concurrently.
- The result is easy to understand, efficient, scalable, and correct.
- The result is maybe even parallel.
One more example: query a replicated DB
Imagine you have a replicated database (multiple shards). You send the request to all instances, but pick the one response that’s first to arrive.
The function accepts an array of connections and the query to execute. It creates a buffered channel of Result, limited to the number of connections. Then it runs over all connections and starts a goroutine for each channel. Goroutine delivers the query, waits for response and delivers the answer to ch. After they all are launched, the function just returns the first value on the channel as soon as it appears.
func Query(conns []Conn, query string) Result {
ch := make(chan Result, len(conns)) // buffered
for _, conn := range conns {
go func(c Conn) {
ch <- c.DoQuery(query):
}(conn)
}
return <-ch
}
(Note that _ on line 3 stands for an unused, unnamed variable).
Conclusion
- Concurrency is powerful.
- Concurrency is not parallelism.
- Concurrency enables parallelism.
- Concurrency makes parallelism (and scaling and everything else) easy.
More information
- Go official page: golang.org
- Some history: Bell Labs and CSP Threads
- A previous talk by Rob Pike: Advanced Topics in Programming Languages: Concurrency/message passing Newsqueak
- Parallelism Is Not Concurrency (article by Robert Harper)
- A Concurrent Window System (paper by Rob Pike)
- Squinting at Power Series (paper by M. Douglas McIlroy)
- Interpreting the Data: Parallel Analysis with Sawzall
If you liked this illustrated summary, consider supporting me by purchasing a set of PDF (preview), HTML epub and Kindle versions in one nice package. Name your price, starting from $1.